Economics of foundation models
Practicalities of competition between ordinary schlubs, and machines which can tirelessly collage all of history’s greatest geniuses at once
March 23, 2023 — February 12, 2025
Suspiciously similar content

Various questions about the economics of social changes wrought by ready access to LLMs, the latest generation of automation. This is a short-to-medium-term frame question, whatever “short” and “medium” mean. Longer-sighted folks might also care about whether AI will replace us with grey goo or turn us into raw feedstock for building computronium.
1 Economics of collective intelligence
Well, it’s really terribly simple, […] it works any way you want it to. You see, the computer that runs it is a rather advanced one. In fact, it is more powerful than the sum total of all the computers on this planet including—and this is the tricky part— including itself.
— Douglas Adams, Dirk Gently’s Holistic Detective Agency
How do foundation models/large language models change the economics of knowledge and art production? To a first-order approximation (reasonable at 03/2023), LLMs provide a way of massively compressing collective knowledge and synthesising the bits I need on demand. They are not yet primarily generating novel knowledge (whatever that means). But they do seem pretty good at being “nearly as smart as everyone on the internet combined”. I cannot imagine a sharp boundary between these ideas, clearly.
Using these models will test various hypotheses about how much collective knowledge depends on our participation in boring boilerplate grunt work, and what incentives are necessary to encourage us to produce and share our individual contributions to that collective intelligence.
Historically, there was a strong incentive for open publishing. In a world where LLMs effectively use all openly published knowledge, we might see a shift towards more closed publishing, secret knowledge, hidden data, and away from reproducible research, open-source software, and open data since publishing those things will be more likely to erode your competitive advantage.
Generally, will we wish to share truth and science in the future, or will economic incentives switch us towards a fragmentation of reality into competing narratives, each with its own private knowledge and secret sauce?
Consider the incentives for humans to tap out of the tedious work of being themselves in favour of AI emulators: The people paid to train AI are outsourcing their work… to AI. This makes models worse (Shumailov et al. 2023). Read on for more.
To turn that around, we might ask: “Which bytes did you contribute to GPT4?”
2 Organisational behaviour
There is a theory of career moats, which are basically unique value propositions that only you have that make you unsackable. I’m quite fond of Cedric Chin’s writing on this theme, which is often about developing valuable skills. But he (and organisational literature generally) acknowledges there are other ways of ensuring unsackability which are less pro-social — attaining power over resources, becoming a gatekeeper, opaque decision making, etc.
Both these strategies co-exist in organisations generally, but I think that LLMs, by automating skills and knowledge, tilt incentives towards the latter. It is rational in this scenario for us to think less about how well we can use our skills and command of open (e.g., scientific, technical) knowledge to be effective, and rather, for us to focus on how we can privatise or sequester secret knowledge to which we control exclusive access if we want to show a value add to the organisation.
How would that shape an organisation, especially a scientific employer? Longer term, I’d expect to see a shift (in terms both of who is promoted and how staff personally spend time) from skill development and collaboration, towards resource control, competition, and privatisation: less scientific publication, less open documentation of processes, less time doing research and more time doing funding applications, more processes involving service desk tickets to speak to an expert whose knowledge resides in documents that you cannot see.
Is this tilting toward a Molochian equilibrium?
3 Darwin-Pareto-Turing test
There is an astonishing amount of effort dedicated to wondering whether AI is conscious, has an inner state or what-have-you. This is clearly fun and exciting.
It doesn’t feel terribly useful. I am convinced that I have whatever it is that we mean when we say conscious experience. Good on me, I suppose.
But out there in the world, the distinction between anthropos and algorithm is not done by the subtle microscope of the philosopher but by the brutally practical, blind groping hand of the market. If the algorithm performs as much work as I, then it is as valuable as I; we are interchangeable, to be distinguished only by the price of our labour. If anything, the additional information that AI was conscious would, as an employer, bias me against it relative to one guaranteed to be safely mindlessly servile since that putative consciousness would imply that it could have goals of its own in conflict with mine.
Zooming out, Darwinian selection may not care either. Does a rich inner world help us reproduce? It seems that it might have for humans; but how much this generalises into the technological future is unclear. Evolution duck-types.
4 What to spend my time on
Economics of production at a microscopic, individual scale. What should I do, now?
GPT and the Economics of Cognitively Costly Writing Tasks
To analyse the effect of GPT-4 on labour efficiency and the optimal mix of capital to labour for workers who are good at using GPT versus those who aren’t when it comes to performing cognitively costly tasks, we’ll consider the Goldin and Katz modified Cobb-Douglas production function…
Is it time for the Revenge of the Normies? - by Noah Smith
Alternate take: Think of Matt Might’s iconic illustrated guide to a Ph.D..



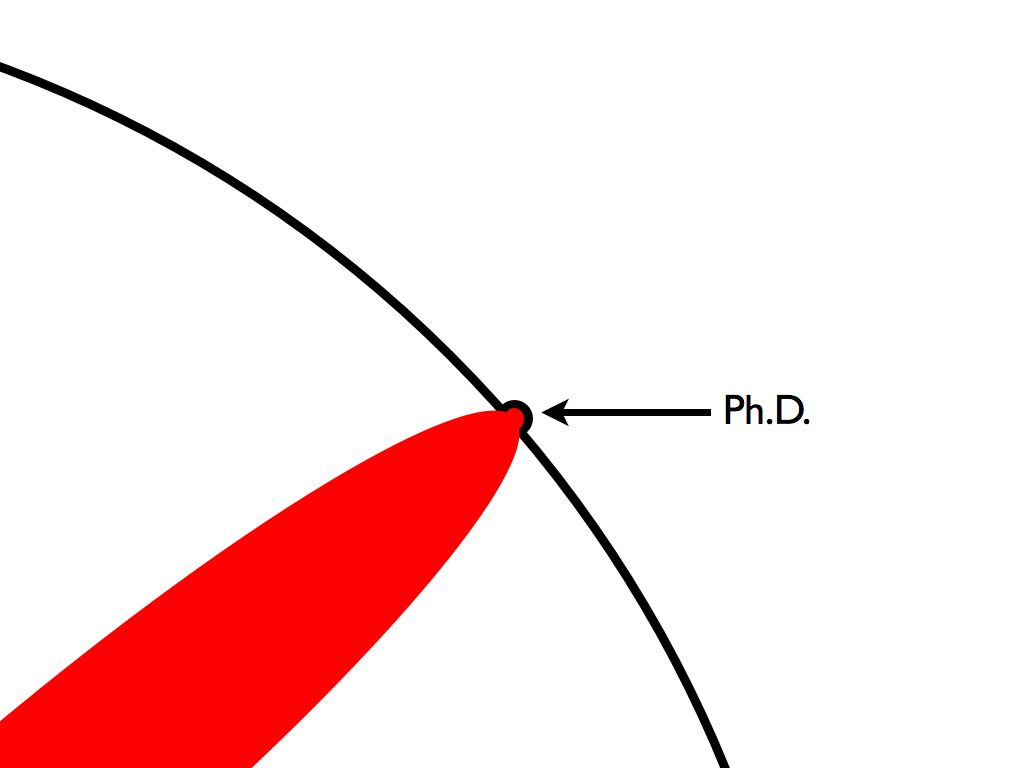
Here’s my question: In the 2020s, does the map look something like this?

If so, is it a problem?
5 Spamularity, dark forest, textpocalypse
See Spamularity.
6 Economic disparity and LLMs
- Ted Chiang, Will A.I. Become the New McKinsey? looks at LLMs through the lens of Piketty as increasing returns to capital vs returns to labour
7 Returns to scale for large AI firms
Deepseek is a Chinese company, not a community. But they seem to be changing the game in terms of cost, accessibility, and openness of AI models. TBD.
- DeepSeek on X: “🚀 DeepSeek-R1 is here! ⚡ Performance on par with OpenAI-o1 📖 Fully open-source model & commercialise freely! 🌐 Website & API are live now!”
- deepseek-ai (DeepSeek)
- Paper page - DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
- deepseek-ai/DeepSeek-R1-Distill-Qwen-32B · Hugging Face
Leaked Google document: “We Have No Moat, And Neither Does OpenAI” asserts that large corporates are concerned that LLMs do not provide sufficient return on capital.
8 PR, hype, marketing

George Hosu, in a short aside, highlights the incredible marketing advantage of AI:
People that failed to lift a finger to integrate better-than-doctors or work-with-doctors supervised medical models for half a century are stoked at a chatbot being as good as an average doctor and can’t wait to get it to triage patients
Google’s Bard was undone on day two by an inaccurate response in the demo video where it suggested that the James Webb Space Telescope would take the first images of exoplanets.
This sounds like something the JWST would do but it’s not at all true
So one tweet from an astrophysicist sank Alphabet’s value by 9%. This says a lot about how
LLMs are like being at the pub with friends, it can say things that sound plausible and true enough, and no one really needs to check because who cares?
Except we do because this is science, not a lads’ night out, and
the insane speculative volatility of this AI bubble that the hype is so razor thin it can be undermined by a tweet with 44 likes.
I had a wonder if there’s any exploration of the ‘thickness’ of hype. Jack Stilgoe suggested looking at Borup et al. (2006) which is evergreen but I feel like there’s something about the resilience of hype:
Like crypto was/is pretty thin in the scheme of things. High levels of hype but frenetic, unstable and quick to collapse.
AI has pretty consistent if pulsating hype gradually growing over the years while something like nuclear fusion is super thick (at least in the popular imagination) – remaining through decades of not-quite-ready and grasping the slightest indication of successI don’t know, if there’s nothing specifically on this, maybe I should write it one day.
9 Tokenomics
10 “Snowmobile or bicycle?”
Thought had in conversation with Richard Scalzo about Smith (2022).
Is the AI we have a complementary technology or a competitive one?
This question looks different at the individual and societal scale.
For some early indications, see Microsoft Study Finds AI Makes Human Cognition “Atrophied and Unprepared” (Lee 2025). I do have many qualms about the actual experimental question they are answering there, but it’s a start.
TBC
11 Democratisation of AI
12 Art and creativity
For now, see timeless works of art.
13 Data sovereignty
See data sovereignty.
14 Incoming
Conference Summary: Threshold 2030 - Modelling AI Economic Futures - Convergence Analysis
Predistribution over Redistribution — The Collective Intelligence Project
Maxwell Tabarrok, AGI Will Not Make Labour Worthless is a good summary of the arguments that AGI is just quantitatively rather than qualitatively different from what has gone before. I would prefer it as “AGI is less likely to abolish human labour value than you previously thought” rather than a blanket statement, but YMMV.
Ilya Sutskever: “Sequence to sequence learning with neural networks: what a decade”
Can the climate survive the insatiable energy demands of the AI arms race?
Why Quora isn’t useful anymore: A.I. came for the best site on the internet.
Tom Stafford on ChatGPT as Ouija board
Gradient Dissent, a list of reasons that large backpropagation-trained networks might be worrisome. Some interesting points in there, and some hyperbole. Also: If it were true that externalities come from backprop networks (i.e. that they are a kind of methodological pollution that produces private benefits but public costs) then what kind of mechanisms should disincentivise them?
-
In this post, we evaluate whether major foundation model providers currently comply with these draft requirements and find that they largely do not. Foundation model providers rarely disclose adequate information regarding the data, compute, and deployment of their models as well as the key characteristics of the models themselves. In particular, foundation model providers generally do not comply with draft requirements to describe the use of copyrighted training data, the hardware used and emissions produced in training, and how they evaluate and test models. As a result, we recommend that policymakers prioritise transparency, informed by the AI Act’s requirements. Our assessment demonstrates that it is currently feasible for foundation model providers to comply with the AI Act, and that disclosure related to foundation models’ development, use, and performance would improve transparency in the entire ecosystem.
I Do Not Think It Means What You Think It Means: Artificial Intelligence, Cognitive Work & Scale
Ben Thompson, OpenAI’s Misalignment and Microsoft’s Gain
Invasive Diffusion: How one unwilling illustrator found herself turned into an AI model
How Elon Musk and Larry Page’s AI Debate Led to OpenAI and an Industry Boom
Hi, I’m Olivia Squizzle, and I’m gonna replace AI – Pivot to AI
Bruce Schneier, On the Need for an AI Public Option
I Went to the Premiere of the First Commercially Streaming AI-Generated Movies