Publication bias
Replication crises, P-values, bitching about journals, other debilities of contemporary science at large
August 30, 2016 — July 21, 2021
Suspiciously similar content
Multiple testing across a whole scientific field, with a side helping of biased data release and terrible incentives.
On one hand, we hope that journals will help us find things that are relevant. On the other hand, we hope the things they help us find are actually true. It’s not at all obvious how to solve these kinds of classification problems economically, but we kind of hope that peer review does it.
To read: My likelihood depends on your frequency properties.
Keywords: “file-drawer process” and the “publication sieve”, which are the large-scale models of how this works in a scientific community and “researcher degrees of freedom” which is the model for how this works at the individual scale.
This is particularly pertinent in social psychology, where it turns out there is too much bullshit with \(P\leq 0.05\).
Sanjay Srivastava, Everything is fucked, the syllabus.
1 Fixing P-hacking and related science-at-large problems

Oliver Traldi reviews Stuart Ritchie’s book Science Fictions which uses the replication crisis in psychology as a lens to understand science’s flaws.
Serious though this is, there is also something more specifically pernicious about the replication crisis in psychology. We saw that the bias in psychological research is in favour of publishing exciting results. An exciting result in psychology is one that tells us that something has a large effect on people’s behaviour. And the things that the studies that have failed to replicate have found to have large effects on people’s behaviour are not necessarily things that ought to affect people’s behaviour, were those people rational. Think of the studies I mentioned above: a mess makes people more prejudiced; a random assignment of roles makes people sadistic; a list of words makes people walk at a different speed; a strange pose makes people more confident. And so on.
Experiment guide maintains a list of refuted claims from observational studies.
Uri Simonsohn’s article on detecting the signature of p-hacking is interesting.
Some might say, just fix the incentives, but apparently that is off the table because it would require political energy. There is open notebook science, that could be a thing.
Failing the budget for that… pre-registration?
Tom Stafford’s 2 minute guide to experiment pre-registration:
Pre-registration is easy. There is no single, universally accepted, way to do it.
you could write your data collection and analysis plan down and post it on your blog.
you can use the Open Science Framework to timestamp and archive a pre-registration, so you can prove you made a prediction ahead of time.
you can visit AsPredicted.org which provides a form to complete, which will help you structure your pre-registration (making sure you include all relevant information).
“Registered Reports”: more and more journals are committing to published pre-registered studies. They review the method and analysis plan before data collection and agree to publish once the results are in (however they turn out).
But should you in fact pre-register?
Morally, for the good of science, perhaps. But not in the sense that it’s something that you should do if you want to progress in your career. Rather the opposite. As argued by Ed Hagen, academic success is either a crapshoot or a scam:
The problem, in a nutshell, is that empirical researchers have placed the fates of their careers in the hands of nature instead of themselves. […]
Academic success for empirical researchers is largely determined by a count of one’s publications, and the prestige of the journals in which those publications appear […]
the minimum acceptable number of pubs per year for a researcher with aspirations for tenure and promotion is about three. This means that, each year, I must discover three important new things about the world. […] […]
Let’s say I choose to run 3 studies that each has a 50% chance of getting a sexy result. If I run 3 great studies, mother nature will reward me with 3 sexy results only 12.5% of the time. I would have to run 9 studies to have about a 90% chance that at least 3 would be sexy enough to publish in a prestigious journal.
I do not have the time or money to run 9 new studies every year.
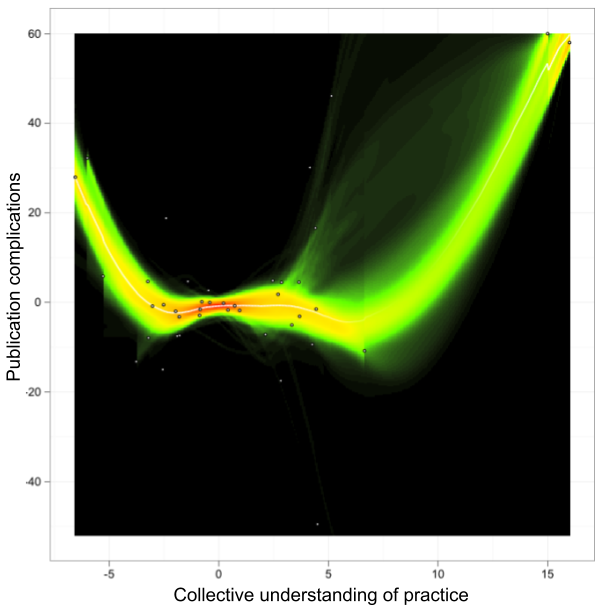
So, when does a certain practice—e.g., a study design, a way to collect data, a particular statistical approach—“succeed” and start to dominate journals?
It must be capable of surviving a multi-stage selection procedure:
- Implementation must be sufficiently affordable so that researchers can actually give it a shot
- Once the authors have added it to a manuscript, it must be retained until submission
- The resulting manuscript must enter the peer-review process and survive it (without the implementation of the practice getting dropped on the way)
- The resulting publication needs to attract enough attention post-publication so that readers will feel inspired to implement it themselves, fueling the eternally turning wheel of
Samsarapublication-oriented science
Erik van Zwet, Shrinkage Trilogy Explainer models the publication process
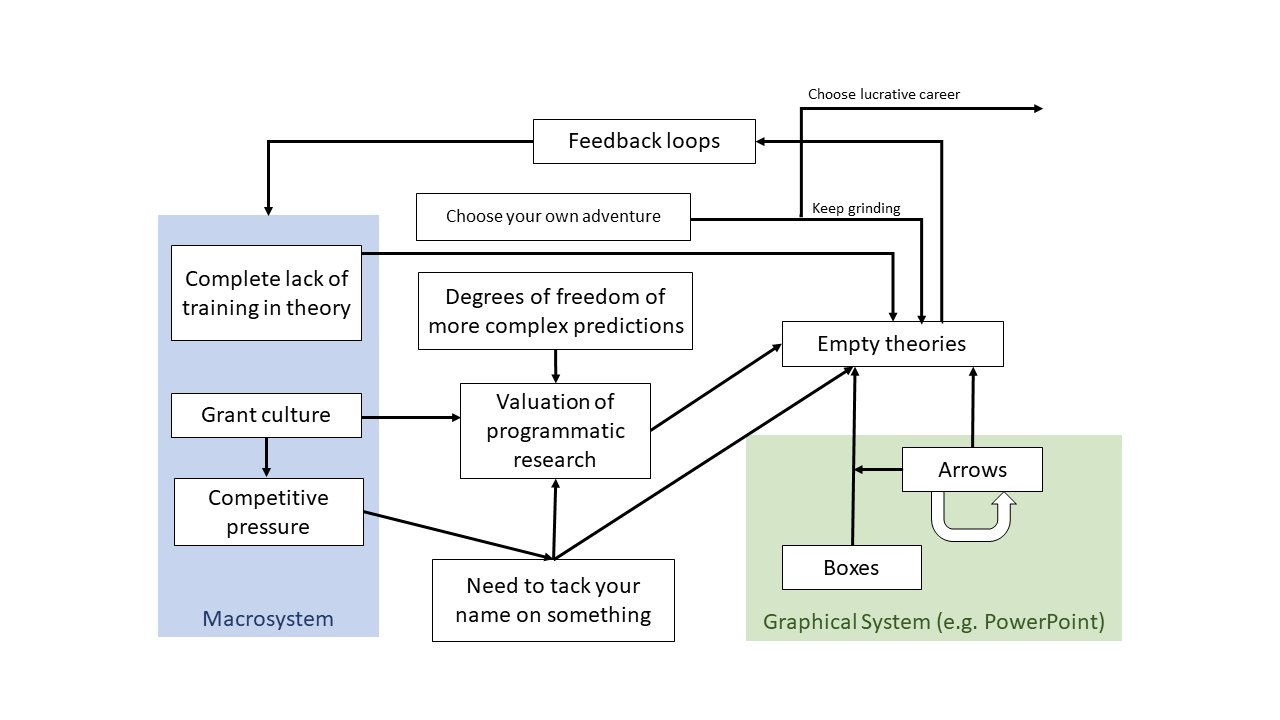
The Control Group Is Out Of Control provides good links for parapsychology as a control group for science.
2 On the easier problem of local theories
On the other hand, we can all agree that finding small-effect universal laws in messy domains like human society is a hard problem. In machine learning, we frequently give up on that and just try to solve a local problem — does this work in this domain with enough certainty to help this problem? Then we still need to solve a problem about domain adaptation when we try to work out if we are still working on this problem, or at least one similar enough to this. But that feels like it might be easier by virtue of being less ambitious.